
From digitization towards digital preservation - building a digital library system for medical information users
Introduction
The development of specialized digital libraries and archives in the Czech Republic has been stated in the official document "Conception of permanent preservation of traditional library collections and electronic documents in Czech libraries". National Medical Library (NML) has been in the process of building a digital library since 2009 using Czech open source software tool - digital library system Kramerius. In order to maintain and evolve our digital library and its content and services it has become necessary to establish an encompassing project to build a solid digital preservation system compliant with the Open Archival Information System Reference model (OAIS).
NML has successfully applied for the Ministry of Health Internal Grant Agency (IGA) project funded between years 2011-2013. The project aims at "creation of a long term digital preservation system in the NML, which will allow permanent archiving and accessibility of full texts of scientific publications in the field of medical disciplines". The main goals of the project are: development of digital preservation system using PLATTER (Planning tool for Trusted Electronic Repositories[1]) process, building digitization workplace and department, implementation of suitable data storage in NML's datacenter, and digitization of 4.000 IGA final grant reports.
Access to the archived content is facilitated by recently developed Medvik web portal (http://www.medvik.cz/bmc) which provides access to Czech medical bibliography database (BMC) and medical union catalogues. Thus the links to full-text can be displayed directly at the articles level where available. NML has put a lot of effort into solving legal aspects by special licensing agreements to make the most of full texts freely accessible to every user. Content of the repository comes in several formats from different sources and efforts - in-house digitization and external digitization projects, collaboration with Czech publishers or contributed directly by authors. The majority of content from publishers and authors are PDF files. There are currently 100 scientific journals and +1000 other documents archived. The complexity of archived digital objects vary from single page images with OCR in separated text files over article and volume level PDF files to whole large documents as one PDF file.
Objectives
The selection of suitable data and metadata formats used by the repository is essential and affects many operations in the Acquisition, Data and Preservation planning objectives defined by PLATTER. For the long term preservation of the IGA final reports and digital born scientific publications NML has chosen PDF/A-1 format [2]. The main reasons are that it is open, standardized, self-contained and indexable format, suitable for page-oriented textual documents and it is usual in scientific communication. Newly acquired reports in digital form will be compliant with PDF/A-1b standard, the objects in PDF formats already archived in the repository will be converted to PDF/A-1b and the PDF documents from authors will be converted during the ingest workflow. The conversion process shall use thoroughly tested tool(s) to provide valid and well-formed files. This research aims at evaluation of available PDF to PDF/A converters which will be the most suitable in terms of consistency and reliability.
Methods
Technical metadata available were not sufficient for the analysis of digital objects stored in the repository. Thus the content has been analyzed using JHOVE [3] open source tool which provides functions to perform format-specific identification, validation, and characterization of digital objects. The list of files stored in the repository has been digested from the file system using simple batch command: repository>dir /b /s /aa > filelist. The list was used as input for a simple batch files implementing JHOVE and converters command line interfaces (CLI).
Several PDF/A manipulating software products mostly in trial versions have been downloaded and evaluated. The testing was performed in two phases: 1) evaluation of available converters based on conversion of PDF files from the Isartor test suite [4]; and 2) test conversion of all PDF files in the repository using the tools selected in the first phase. The converted Isartor files have been cross-validated that the best-performing PDF/A converters could be identified. The best applicable tools have made progress to the second phase. The conversion logs and reports have been processed and imported into SQL database for further analysis.
Results
The analysis revealed there are 189,917 digital objects in the repository - DjVu, TXT, PDF and Jpeg files - with total size of 43.6 gigabytes (GB), of which PDF files are 9079 with the size of 17.6 GB. The JHOVE version used in the analysis supported only PDF up to version 1.6 so the results had to be enhanced by 3-Heights PDF Validator which can output the files claimed conformance level. The results of combined analysis are displayed in Fig. 1 (1b = PDF/A-1b). There were found 15 corrupted PDF files.
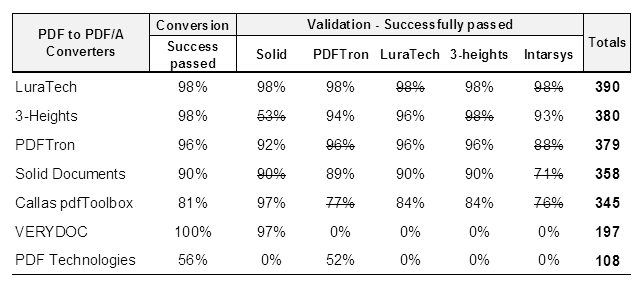
Comparison based on conversion and cross-validation of Isartor test suite involved processing of 203 files (1 removed - isartor-6-1-12-t01-fail-a - some tools became unresponsive when converting it). The test suite is specially designed to reveal flaws in a PDF/A manipulating tools. All selected tools correctly marked the 203 files as invalid. The comparison of conversion results can be seen in Tab. 1. The total score is the sum of percentages of successfully passed and validated files (self-validation and the worst result for each converter were excluded). Intarsys tool was used for validation only due to trial restricted conversion limit. Callas tool speed performance was unsatisfactory and was not used in the cross-validation. The comparison has shown quite differences between the tools.
Results of PDF Technologies and VERYDOC products were very bad and the tools cannot be recommended even for personal use. Solid Documents performed poor and inconsistent validation but delivered good conversion results - the tool might do well as desktop solution in personal or office use. Callas performed unsatisfactorily in conversion success rate though it offers many additional functions (which have not been relevant for this research).
The three of the tools passed into the second testing phase but only PDFTron and 3-Heights were finally compared because LuraTech product did not provide any CLI (only graphic interface with folder and subfolders input) and could not process the repository file list - moving the files out from the repository system has not been an option. 3-Heights product converted successfully 99.3% of the files with 48 failed and the conversion lasted 8 hours. PDFTron converted successfully 93.1% of the files with 610 failed and the conversion lasted 1.3 hours. Estimated conversion time for LuraTech based on the first phase test is 1.5 hour; for Callas 37.5 hours.
Discussion
There were previous efforts trying to determine chances of success for migration of a PDF files collections to PDF/A [5] though only one commercial tool had been used which is not available any more. Our research used the Isartor test suite for evaluation of current commercially available software tools - no mature open source software have been found. The results proved that using the test suite is good starting point in evaluation of PDF/A conversion capabilities and it can impact conversion result significantly. The final decision must be based on testing of repository's own digital objects and depends very much on specific conversion needs - in our scenario the ability to batch process a list of PDF files. There are other features and aspects of evaluated tools that might have influence on the decision - enhancing OCR and metadata capabilities, CLI/desktop/server service modes of operations, SDK availability etc. LuraTech tool has shown promising results and it might be possible to use its software development kit (SDK) and write custom code for the conversion task. The quality testing of our output test files needs to be done yet and we plan to compare 5% of converted files at least to be visually identical to the original before finally selecting the conversion tool.
Acknowledgement
This research was supported by the Ministry of Health Internal Grant Agency, Czech Republic, project no. NT12345
| Attachment | Size |
|---|---|
| 984_Kriz et al_Figure.jpg | 42.2 KB |
| 984_Kriz et al_Table.jpg | 67.12 KB |
- DigitalPreservationEurope. Repository Planning Checklist and Guidance DPED3.2. 2008 Apr [cited 2012 Apr 27]. Available from: http://www.digitalpreservationeurope.eu/publications/reports/Repository_Planning_Checklist_and_Guidance.pdf
- PDF/A-1, PDF for Long-term Preservation, Use of PDF 1.4 [Internet]. Library of Congress, Digital Preservation. [last updated 2009 Feb 25; cited 2012 Apr 27]. Available from: http://www.digitalpreservation.gov/formats/fdd/fdd000125.shtml
- JHOVE - JSTOR/Harvard Object Validation Environment [Internet]. JSTOR. [last updated 2009 Feb 25; cited 2012 Apr 27]. Available from: http://hul.harvard.edu/jhove/
- Isartor Test Suite [Internet]. PDF Association. 2011 [cited 2012 Apr 27]. Available from: http://www.pdfa.org/2011/08/isartor-test-suite/
- Walker FL, Gallagher ME, Thoma GR. PDF File Migration to PDF/A: Technical Considerations. Proc. IS&T Archiving; 2007 May; Arlington, Virginia. 2007 [cited 2012 Apr 27]. p. 6-11. Available from: http://www.lhncbc.nlm.nih.gov/lhc/docs/published/2007/pub2007020.pdf
- 28017 reads
Search
Popular content
All time:
- From digitization towards digital preservation - building a digital library system for medical information users
- Discussion around a Belgian beer
- The Brazilian blog Ecce Medicus and the information on H1N1 flu vaccine for lay people: a case study in Health Communication
- Despite the skepticism
- EAHIL 2012 Conference - Health information without frontiers: 4 - 6 July, 2012, UCL, Brussels, Belgium
- Registration
- Venue
- Schedule
- Library Tours
Recent blog posts
- This is it!
- Welcome reception: Wednesday July 4
- Click the city: Brussels has been tagged!
- Some tips when visiting Brussels
- Preparation of the proceedings
- Newsletter tool has been set up!
- A mobile app for EAHIL2012!
- Sponsoring and exhibiting at EAHIL 2012 Conference
- Message to presenters: Information for presenters has been updated
- E-mails were from website blocked, problem is now solved





{kind=link}
{kind=link}
Recent comments
6 years 25 weeks ago